



基于虚拟化技术的 KVM:开源系统虚拟化模块的特点与优势
·2024-09-29 11:03:38 浏览次数: TGA:穿越火线透视软件下载手游穿越火线端游透视穿越火线透视自瞄视频
浅谈无记忆对抗与AI自瞄FPS作弊方案的原理及常见的反作弊措施和反作弊对策(下)
3、基于虚拟化技术的KVM-内存插件
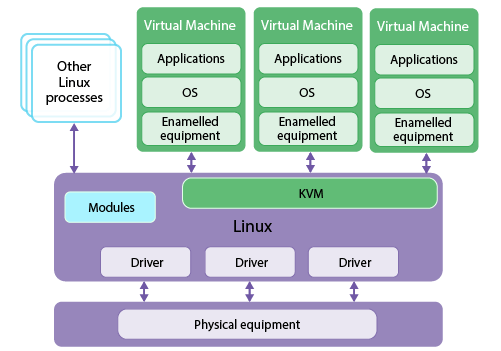
-based 是一个开源系统虚拟化模块,自 Linux 2.6.20 以来已集成到所有主要 Linux 发行版中。它使用Linux自带的调度器进行管理,因此与Xen相比,其核心源代码非常少。 KVM已经成为学术界主流的VMM之一。
KVM虚拟化需要硬件支持(如Intel VT技术或AMDV技术)。它是基于硬件的完全虚拟化。 Xen早期是基于软件模拟的Para,而新版本则是基于硬件支持的全虚拟化。不过Xen本身有自己的进程调度器、存储管理模块等,所以代码比较庞大。广泛流传的商业系统虚拟化软件ESX系列是完全基于软件模拟的。
在游戏作弊领域,由于各种作弊功能的实现依赖于获取游戏的内存数据,因此获取数据的方法大多是由插件作者编写或者购买专门设计的内存读写驱动来绕过反作弊,来自操作系统的内核状态。读取数据。然而,这样的司机往往会受到反作弊团队的高度关注。从某些方面来说,反作弊程序可以是专门用来对抗驱动程序的程序,因此大多数情况下,编写良好的驱动程序往往会被使用很长时间。短时间后,就会被反作弊程序定位,然后封禁。司机对抗领域的反作弊成本依然居高不下。为了降低对抗成本、简化插件开发流程、追求更稳定的插件生命周期,插件作者纷纷关注KVM虚拟机技术。
简单来说,KVM将游戏程序放置在一个干净的、独立的、专门为游戏运行而提供的虚拟机中。专门用于运行游戏的虚拟机系统经过深度优化和定制,彻底消除了游戏反作弊系统可能检测并标记为虚拟机的任何特征。毫无疑问它和普通操作系统一样,是一个高度简化的操作系统。它使得游戏对计算机资源的利用更加高效,往往游戏的画面表现和游戏帧率都会得到极大的优化。
当游戏运行在虚拟机上时,游戏通常会将游戏过程中所需的各种数据保存到内存中,插件作者可以通过读取虚拟机的内存数据并添加特定的偏移量来间接保存数据。获取游戏的内存数据。这种读取行为从游戏反作弊的角度来看是完全“无痕”的,因为外挂直接读取虚拟机程序的内存数据,而不是直接读取游戏数据。从反作弊的角度来看,这只是操作系统正常的调用行为。游戏运行在虚拟机中,在主机上运行插件,在主机屏幕上绘制视角、物品信息等信息,然后将虚拟机的游戏画面做成全屏。视觉效果与传统内存插件的界面无异。
KVM技术相当于在沙箱中运行游戏及其反作弊,与本地操作系统环境完全隔离。各种反作弊检测方法在沙盒中毫无用处,只能通过行为检测等方式来使用。被动检测方法用于检测异常行为,但插件在这方面往往滴水不漏,具有高度真实的鼠标移动轨迹,间接的敌方目标显示(如CSGO的声纳插件),以及作弊者主观高超的“演技”,使得反作弊行为检测效果不佳。
从代码层面来说,传统外挂作者只需要找到一种方法来定位游戏内存地址在虚拟机中的偏移量,其余的编写方法可以直接参考内存外挂的正常编写方法。来实现KVM内存插件。
然而,KVM技术现在不仅仅局限于内存作弊。事实证明,传统的找色插件和新兴的AI插件也可以与KVM虚拟机技术相结合,以避免反作弊检测。
4.基于物理外设硬件的DMA插件
原理部分直接从百度百科贴出来。
直接内存访问(DMA)是某些计算机总线体系结构提供的一项功能,可以将数据从连接的设备(例如磁盘驱动器)直接发送到计算机主板的内存。
外设与存储器之间、存储器与存储器之间的数据传输通常采用程序中断方式、程序查询方式和DMA控制方式。程序中断模式和程序查询模式都需要CPU发出输入/输出(In/Out,I/O)指令,然后等待I/O设备完成操作才返回。在此期间,CPU需要等待I/O设备完成操作。当DMA从内存和I/O设备传输数据时,不需要CPU控制数据传输。它直接通过DMA控制器(DMAC)完成外设与内存之间、内存与内存之间的高速数据传输。 [3]
DMA传输原理
一次完整的DMA传输包括4个步骤:DMA请求、DMA响应、DMA传输和DMA结束。 DMA传输原理如图1所示,图中的I/O设备为源设备,I/O设备将数据传输到目的设备(内存)。 DMA的基本传输过程如下:①CPU初始化总线控制器,制定工作内存空间,读取DMAC中的寄存器信息,了解DMAC的传输状态[1]; ② I/O设备向DMAC发送DMA请求(DMA、DREQ)。 DMAC收到该信号后,向CPU发送总线保持信号。信号(保持); ③当前总线周期执行完毕后,CPU发送总线响应信号保持确认(hold,HLDA); ④DMAC收到总线授权后向I/O设备发送DMA响应信号DMA确认(DMA、DACK),表示允许。 I/O设备进行DMA传输; ⑤开始传输时,DMAC首先从源地址读取数据并存储到内部缓存中,然后写入目的地址,完成总线数据从源地址到目的地址的传输[1]; ⑥DMA 传输完成后,DMAC 向CPU 发送结束信号并释放总线,让CPU 重新获得对总线的控制权。一次DMA传输只需要执行一个DMA周期,相当于一个总线读/写周期,因此可以满足外设数据高速传输的需求。 [3]
DMA是所有现代计算机的一个重要特性,它允许不同速度的硬件设备进行通信,而不依赖于中央处理器上的大量中断负载。否则,CPU 需要将每个片段的数据从源复制到寄存器,然后将它们再次写回新位置。在此期间,CPU 无法用于其他工作。
DMA 传输通常用于将内存区域从一个设备复制到另一个设备。当CPU初始化传输动作时,传输动作本身由DMA控制器执行并完成。一个典型的例子是将外部存储器块移动到芯片内更快的存储器。像这样的操作不会停止处理器的工作,从而允许它重新安排时间来处理其他工作。 DMA 传输对于高性能嵌入式系统算法和网络非常重要。例如,个人计算机控制器有 8 个 DMA 通道,其中 7 个可供计算机的中央处理器使用。每个 DMA 通道都有一个 16 位地址寄存器和一个 16 位计数寄存器。为了启动数据传输,设备驱动程序将 DMA 通道的地址和计数寄存器一起设置,以及数据传输、读取或写入的方向。然后指示DMA硬件开始这次传输动作。当传输完成后,设备会以中断的形式通知中央处理器。
“分散-聚集”(-) DMA 允许在单个 DMA 事务中将数据传输到多个存储区域。相当于将多个简单的DMA请求串在一起。同样,这样做的目的是为了减轻 CPU 的多个 I/O 中断和数据复制任务。 DRQ表示DMA请求; DACK表示DMA确认。这些符号通常可以在具有 DMA 功能的计算机系统的硬件轮廓上看到。它们代表CPU和DMA控制器之间的电子信号传输线。
为了提高DMA设备的数据复制效率,基于DMA原理设计了一种具有PCIE接口的外部DMA设备。通过专用芯片和独立的PCIE通道,再加上Type-C高速USB接口,数据复制速度达到新高。 。 DMA设备最初的设计是绕过CPU直接访问内存数据,用于工业等领域的数据采集或数据同步。
由于FPS领域的游戏外挂核心是游戏内存数据的读写,因此外挂的稳定性也关系到读写行为是否会被反作弊系统检测到。由于DMA可以直接绕过CPU,因此可以直接物理绕过操作。系统驱动层面的反作弊检测和基于内核写入的检测也效果不佳。
DMA作弊常常与双机技术相结合。 DMA获取主机上的游戏内存数据后,将数据同步传输到次日机,即从机。在副机上运行的插件程序可以分析数据,然后将屏幕绘图输出到副机,并通过视频融合设备:一种可以将插件绘图屏幕与输入屏幕混合在一起的专用设备然后输出它。它将屏幕与主机的游戏画面融合并输出到显示器。或者使用Kmbox等第三方键盘鼠标设备模拟鼠标移动来控制主机实现自动瞄准等功能。
对于主机来说,既没有直接的内存数据读写,也没有可疑的重叠窗口绘制(内存插件经常在透明窗口上绘制人物坐标框、物品等信息,然后将该窗口堆叠在游戏窗口之上,反作弊对这种绘图行为有针对性的检测),所以对于DMA的早期作弊,反作弊无法有效检测。
而且从插件作者的角度来看,有了DMA设备之后,就不需要再专注于数据的读取了,因为传统的内存插件作者往往需要费尽心思去寻找反内存的检测代码。作弊程序利用驱动程序和汇编知识对检测代码进行处理,例如直接用汇编语言部分检测代码。 DMA设备通常会提供封装好的DLL供程序员调用。插件作者只需获取游戏的进程ID,加上具体数据的内存地址和偏移量,就可以轻松获取关键数据来开发插件功能。
以Apex英雄为例:
int main(){
const char* cl_proc = "cleaner.exe";
const char* ap_proc = "R5Apex.exe";
//const char* ap_proc = "EasyAntiCheat_launcher.exe";
PrintVarsToConsole();
//Client "add" offset
uint64_t add_off = 0x5650;
std::thread aimbot_thr;
std::thread actions_thr;
std::thread itemglow_thr;
std::thread vars_thr;
std::thread recoil_thr;
std::thread debug_thr;
while(active)
{
if(apex_mem.get_proc_status() != process_status::FOUND_READY)
{
if(aim_t)
{
aim_t = false;
actions_t = false;
item_t = false;
recoil_t = false;
g_Base = 0;
aimbot_thr.~thread();
actions_thr.~thread();
//itemglow_thr.~thread();
//recoil_thr.~thread();
debug_thr.~thread();
}
std::this_thread::sleep_for(std::chrono::seconds(1));
printf("Searching for apex process...\n");
apex_mem.open_proc(ap_proc);
if(apex_mem.get_proc_status() == process_status::FOUND_READY)
{
g_Base = apex_mem.get_proc_baseaddr();
printf("\nApex process found\n");
printf("Base: %lx\n", g_Base);
aimbot_thr = std::thread(AimbotLoop);
actions_thr = std::thread(DoActions);
//itemglow_thr = std::thread(item_glow_t);
//recoil_thr = std::thread(RecoilLoop);
if (DEBUG_PRINT)
{
debug_thr = std::thread(DebugLoop);
debug_thr.detach();
}
aimbot_thr.detach();
actions_thr.detach();
//itemglow_thr.detach();
//recoil_thr.detach();
}
}
else
{
apex_mem.check_proc();
}
std::this_thread::sleep_for(std::chrono::milliseconds(12));
}
return 0;代码中的类是基于封装的DMA-DLL编写的内存读写类。在插件代码中,作者不再需要进行反作弊的特殊处理,可以专注于功能的开发。
可笑的是,随着DMA技术的推行以及国外插件作者的积极开源,国内越来越多的人冒着触犯刑法的风险,通过各种渠道获取最新版本的游戏。替换源代码中过时的数据后,插件被编译并出售。而且DMA外挂的价格比传统内存外挂的价格要贵一些。每月300、500的定价,其实是一个“性价比”的选择。
最初,DMA只活跃于《逃离塔科夫》、《PUBG》、《CSGO》游戏的国外作弊圈。后来国外插件作者在网上开源了相关插件源码,同时也开源了DMA板的原理图和固件源码。通过He平台引入国内,国内插件作者将基于开源代码的二次开发应用于穿越火线、逆袭、CFHD、霍元甲契约等国服FPS游戏,插件类型不限除了传统的视角自我瞄准外,还延伸到了雷达、物品着色、无后座等多种功能。由于FPS游戏的关键数据是本地计算的特点,因此可以通过数据无限创造来获取内存数据。
DMA硬件的固件烧录、与DMA配合的插件程序代码的销售以及各种第三方键盘鼠标盒及外设,形成了完整的双机、DMA插件作弊黑色产品链。在DMA作弊横行的那些年里,普通玩家可以说是吃尽了苦头。
近年来,随着国内ACE反作弊团队对DMA作弊新作弊方式的高度重视,DMA作弊得到了一定程度的打击。然而,已经蔓延的庞大黑市,却让人们对这种新型作弊行为警觉起来。打击作弊的战争才刚刚开始。隐藏在地表深处的毒瘤依然巨大,作弊攻防之路依然十分坎坷。
5.基于Yolo目标检测框架的AI自瞄准插件
基于Yolo目标检测框架在FPS游戏中实现AI自我瞄准的相关视频可以追溯到2019年(事实上,2016年Yolo问世后,就有相关帖子讨论其在游戏作弊领域的应用,但最早是将Yolo框架与梦幻西游、DNF等实体游戏结合起来,利用目标检测来完成自动寻路、闲置脚本、打金等功能。)不过,并没有多少人关注对当时的它。 Yolo框架不久前刚刚问世。无论是效率还是速度上都有所欠缺,所以当时在FPS领域的效果只是类似于主机控制器的辅助瞄准效果,并没有达到影响平衡的地步。更多的是验证Yolo框架在FPS领域应用自瞄准等作弊功能的可行性。当时国内流行的FPS游戏作弊仅停留在内存插件作弊层面,其以驱动内存为核心。当时DMA还没有推广,游戏厂商也只是针对内存外挂。
后来随着-tiny、v7、v8等版本框架的推出,结合CUDA加速、定量加速、加速等技术的支持,效率、速度、准确度都得到了保证。凭借专为FPS游戏制作的模型,AI自我瞄准这种新型外挂时隔21年疯狂传播,以它为代表的AI外挂制作团队利用其疯狂赚钱,9月被捕2023年。不过,抓捕并没有抑制国内AI自瞄作弊的发展势头。随着更加便捷的易语言Yolo模块的封装,近年来以易语言为主要编程语言开发的AI自瞄准插件遍布国内插件市场。
相比需要较高编程门槛的内存插件,基于Yolo目标检测框架的AI自瞄准代码更容易实现,不需要过高的门槛。再加上互联网技术平台上随手可得的教程,每个人都可以制作并可以与您的找色插件进行比较。
AI自瞄准插件大致分为8个步骤:
(由于网上各种教程都很详细,所以这里就不列出详细代码,只是从原理角度分析一下流程)
1.实现电脑桌面部分图片的循环截取。由于自瞄准只需要以游戏十字准线为中心的正方形区域的图像,因此不需要全屏截取,以节省计算机资源开销,为游戏和Yolo推理预留足够的资源。一般情况下,可以截取最大范围内或以内尺寸的图像(320和640是由Yolo模型训练时默认的推理尺寸决定的。大多数开源二改作者并不精通Yolo目标检测框架,并且更多是在应用层面。”《程序员》,尽管Yolo框架在推理时可以输入不同尺寸的图像,但大多数作者在这里并不会处理图像,所以大多数开源代码主要输入320或640尺寸的图像)。使用的第三方截图库包括Mss、DXGI,以及团队制作的版本中使用的注入Obs,截图图像是直接从显卡图像输出层Hook获取图像即可。速度足够快,可以满足1秒采集60张图片,即稳定截图速度达到60帧以上,即可实现内存级AI锁定自拍效果。相关代码可以在以下帖子中找到:
使用MSS截图 mss截图-CSDN博客
调用dxgi快速实时截图-CSDN库
C++下使用DXGI实现截图_dxgi截图指定范围-CSDN博客
截图的方式有很多种,AI自拍常用的截图方式就包括以上几种。
2. 获取捕获的桌面图像后,需要对图像进行预处理。经常做的就是将图像转换为numpy多维数组数据结构,将图像的四通道色域转换为三通道RGB格式。语言中,如果当前设备的Cuda加速可用,一般会使用基于cuda加速的numpy库nupy来加速图像处理。将处理后的图像传入Yolo推理框架进行推理。屏幕截图通常用于多线程推理。 1个线程用于截图,1个线程用于推理,1个线程用于监控鼠标和键盘,1个线程用于移动。多线程不仅提高了截图和推理的效率,也最大限度地利用了硬件资源。
3.Yolo框架推理阶段。现阶段国内AI自瞄常用的Yolo推理框架有-tiny、-6.1\6.2版本、Yolo-X、以及。最流行的是基于 CUDA 加速和量化加速,针对显卡。对于 AMD 处理器和显卡,通常使用 ML 加速。虽然效率远不如前两者,但却给了国内AMD显卡用户一个选择,尽管大多数用户还在使用显卡。确定要使用的推理框架后,搜索相关关键词,找到对应框架作者的部署源码。复制源码,按照作者给出的环境部署教程在本地部署CUDA加速工具包和环境。复制源码并获取上一篇文章。将截图数据传入参数后,即可得到预测框的坐标。得到坐标后,就可以进行下一步的数据处理。
4. 获取坐标后,可以根据当前分辨率下桌面的精确坐标,根据拍摄图像的大小推算出预测的帧坐标。这些坐标就是屏幕上识别出的“敌人”的坐标。国内常用的坐标计算方案是通过游戏FOV视角进行三维到二维的坐标平面变换,因为得到的推理坐标是基于游戏内FOV缩放后的坐标。经过数学转换后,就可以得到游戏中的具体坐标,即需要鼠标。相对于当前十字准线需要移动的距离,即玩家需要控制准星从发现敌人到移动到敌人身边的操作。参考博客(只是原理,具体坐标公式我没有保存):
视角与镜头焦距的换算_视场角160°左右的镜头焦距是多少-CSDN博客
5. 获得坐标后,就可以对零件进行加工了。自瞄准插件可以根据需要选择瞄准头部、胸部等部位。坐标转换一般很简单。返回的预测框坐标包括预测框的高度,大约是 x 0.22~0.25,即从预测框顶部向下大约三分之一处是从头到脖子的位置; x 0.4~0.5 大约是身体的位置,以此类推更多位置,按比例计算。
6、经过一系列计算,得到需要移动的相对坐标。下一步是调用鼠标移动部分。以国产游戏为例,比如穿越火线、CFHD、狙击2等游戏。可以直接调用Win32系统API中的函数,通过系统预留的接口模拟鼠标移动。在这些游戏中,你可以正常移动,不会触发检测(似乎根本没有鼠标输入检测)。对于汉化版的《无畏契约》、《反恐精英》等游戏,无法使用系统API进行移动。 《无畏契约》首先会封锁这种虚拟鼠标模拟方式,而《反恐精英》则会检测模拟信号输入并触发反作弊。因此,你需要使用键盘鼠标盒,例如上面提到的Kmbox。这种盒子的特点是它是一个外部硬件设备,并且是可编程的,这意味着程序员只需调用dll就可以控制真正连接到计算机上的键盘和鼠标硬件发送信号来控制鼠标的移动他们提供。这个鼠标信号的输入和我们正常使用鼠标时的输入完全一样,所以游戏反作弊不会被屏蔽,达到自我瞄准的目的。
类似的键盘鼠标盒还有:易键盘鼠标、飞逸莱、北京文盒、无雅键盘鼠标盒、Kmbox系列、系列、幽灵键鼠、Rebel 等。这些键盘鼠标盒可以在淘宝等网购平台上购买。
7.轨迹模拟。获得的坐标不能直接用于自拍,因为生硬快速的自拍会直接触发玩家行为的反作弊检测,所以AI自拍作者需要对移动坐标进行“软化”可以允许自我瞄准。瞄准轨迹不那么僵硬,更接近真人移动鼠标的轨迹。保证了自我瞄准的准确性和速度,同时减少了反作弊行为检测。常用的方法是将绝对运动改为相对运动,模拟运动关键坐标的二阶、三阶贝塞尔曲线,模拟PID控制算法,模拟非线性ARDC控制算法,然后模拟一段自瞄准坐标。将其分解为多个小的移动坐标,分阶段移动(因为鼠标的返回速度一般是每秒1000次鼠标移动,所以模拟的轨迹其实还留有很多冗余,可以放一块自动将瞄准坐标分为100或500个运动,密集点可以看成曲线,更接近真人的运动轨迹)以避免反作弊检测。
截至截止日期,有一种新的模拟鼠标移动的方式,它是基于操作系统内核状态级别的,即R0层的驱动程序IO模拟。它为操作系统安装一个虚拟的人类输入设备,从内核态模拟IO设备输入。并将信号传输到当前连接电脑的设备上,即在正常的鼠标输入信号中插入模拟信号,实现额外的鼠标移动。该方法可以突破《无畏契约》基于屏蔽异常鼠标输入方式的反作弊措施,无需外部硬件即可达到单机AI自我瞄准的效果。
8、以上部分组合基本可以实现AI自瞄准。但针对日益强大的反作弊,AI自瞄插件作者通常会对AI自瞄版本进行进一步封装,以进一步躲避反作弊检测。事实证明,2021年AI自拍刚问世时,反作弊并没有针对AI自拍进行针对性检测。即使是最基本的AI自我瞄准也可以规避反作弊,因为这种新的作弊方法并不对游戏数据进行任何测试。读写不会触发传统的反作弊检测规则。随着AI自我瞄准逐渐进入公众视野,反作弊对新型AI作弊进行了针对性检测,作者也提出了很多反作弊攻击和防御的技术。下一节将重点进行分析。
